(In the previous post, Better ways of using R on LibStats (1), I explain the background for this reference desk statistics analysis with R, and I set up the data I use. This follows on, showing another example of how I figured out how to do something more cleanly and quickly.)
In Ref desk 4: Calculating hours of interactions (from almost exactly two years ago) I explained in laborious detail how I calculated the total hours of interaction at the reference desks. I quote myself:
Another fact we record about each reference desk interaction is its duration, which in our
libstatsdata frame is in thetime.spentcolumn. As I explained in Ref Desk 1: LibStats these are the options:
- NA (“not applicable,” which I’ve used, though I can’t remember why)
- 0-1 minute
- 1-5 minutes
- 5-10 minutes
- 10-20 minutes
- 20-30 minutes
- 30-60 minutes
- 60+ minutes
We can use this information to estimate the total amount of time we spend working with people at the desk: it’s just a matter of multiplying the number of interactions by their duration. Except we don’t know the exact length of each duration, we only know it with some error bars: if we say an interaction took 5-10 minutes then it could have taken 5, 6, 7, 8, 9, or 10 minutes. 10 is 100% more than 5: relatively that’s a pretty big range. (Of course, mathematically it makes no sense to have a 5-10 minute range and a 10-20 minute range, because if something took exactly 10 minutes it could go in either category.)
Let’s make some generous estimates about a single number we can assign to the duration of reference desk interactions.
Duration Estimate NA 0 minutes 0-1 minute 1 minute 1-5 minutes 5 minutes 5-10 minutes 10 minutes 10-20 minutes 15 minutes 20-30 minutes 25 minutes 30-60 minutes 40 minutes 60+ minutes 65 minutes This means that if we have 10 transactions of duration 1-5 minutes we’ll call it 10 * 5 = 50 minutes total. If we have 10 transactions of duration 20-30 minutes we’ll call it a 10 * 25 = 250 minutes total. These estimates are arguable but I think they’re good enough. They’re on the generous side for the shorter durations, which make up most of the interactions.
To do all those calculations I made a function, then a data frame of sums, then I loop through all the library branches, build up new a new data frame for each by applying the function to the sums, then put all those data frames together into a new one. Ugly! And bad!
When I went back to the problem and tackled it with dplyr I realized I’d made a mistake right off the bat back then: I shouldn’t have added up the number of “20-30 minute” durations (e.g. 10) and then multiplied by 25 to get 250 minutes total. It’s much easier to use the time.spent column in the big data frame to generate a new column of estimated durations and then add those up. For example, in each row that has a time.spent of “20-30 minutes” put 25 in the est.duration column, then later add up all those 25s. Doing it this way means only ever having to deal with vectors, and R is great at that.
Here’s the data I’m interested in. I want to have a new est.duration column with numbers in it.
> head(subset(l, select=c("day", "question.type", "time.spent", "library.name")))
day question.type time.spent library.name
1 2011-02-01 4. Strategy-Based 5-10 minutes Scott
2 2011-02-01 4. Strategy-Based 10-20 minutes Scott
3 2011-02-01 4. Strategy-Based 5-10 minutes Scott
4 2011-02-01 3. Skill-Based: Non-Technical 5-10 minutes Scott
5 2011-02-01 4. Strategy-Based 5-10 minutes Scott
6 2011-02-01 4. Strategy-Based 5-10 minutes ScottI’ll do it with these two vectors and the match command, which the documentation says “returns a vector of the positions of (first) matches of its first argument in its second.” Here I set them up and show an example of using them to convert the words to an estimated number.
> possible.durations <- c("0-1 minute", "1-5 minutes", "5-10 minutes", "10-20 minutes", "20-30 minutes", "30-60 minutes", "60+ minutes")
> duration.times <- c(1, 4, 8, 15, 25, 40, 65)
> match("20-30 minutes", possible.durations)
[1] 5
> duration.times[5]
[1] 25
> duration.times[match("20-30 minutes", possible.durations)]
[1] 25That’s how to do it for one line, and thanks to the way R works, if we say we want this to be done on a column, it will do the right thing.
> l$est.duration <- duration.times[match(l$time.spent, possible.durations)]
> head(subset(l, select=c("day", "question.type", "time.spent", "library.name", "est.duration")))
day question.type time.spent library.name est.duration
1 2011-02-01 4. Strategy-Based 5-10 minutes Scott 8
2 2011-02-01 4. Strategy-Based 10-20 minutes Scott 15
3 2011-02-01 4. Strategy-Based 5-10 minutes Scott 8
4 2011-02-01 3. Skill-Based: Non-Technical 5-10 minutes Scott 8
5 2011-02-01 4. Strategy-Based 5-10 minutes Scott 8
6 2011-02-01 4. Strategy-Based 5-10 minutes Scott 8Now with dplyr it’s easy to make a new data frame that lists, for each month, how many ref desk interactions happened and an estimate of their total duration. First I’ll take a fresh sample so I can use the est.duration column
> l.sample <- l[sample(nrow(l), 10000),]
> sample.durations.pm <- l.sample %.% group_by(library.name, month) %.% summarise(minutes = sum(est.duration, na.rm =TRUE), count=n())
> sample.durations.pm
Source: local data frame [274 x 4]
Groups: library.name
library.name month minutes count
1 ASC 2011-09-01 77 7
2 ASC 2011-10-01 66 2
3 ASC 2011-11-01 13 7
4 ASC 2012-01-01 41 3
5 ASC 2012-02-01 11 5
6 ASC 2012-03-01 1 1
7 ASC 2012-04-01 4 1
8 ASC 2012-05-01 23 3
9 ASC 2012-06-01 8 2
10 ASC 2012-07-01 4 1
.. ... ... ... ...
> ggplot(sample.durations.pm, aes(x=month, y=minutes/60)) + geom_bar(stat="identity") + facet_grid(library.name ~ .) + labs(x="", y="Hours", title="Estimated total interaction time (based on a small sample only)")The count column is made the same way as last time, and the minutes column uses the sum function to add up all the durations in each grouping of the data. (na.rm = TRUE removes any NA values before adding; without that R would say 5 + NA = NA.)
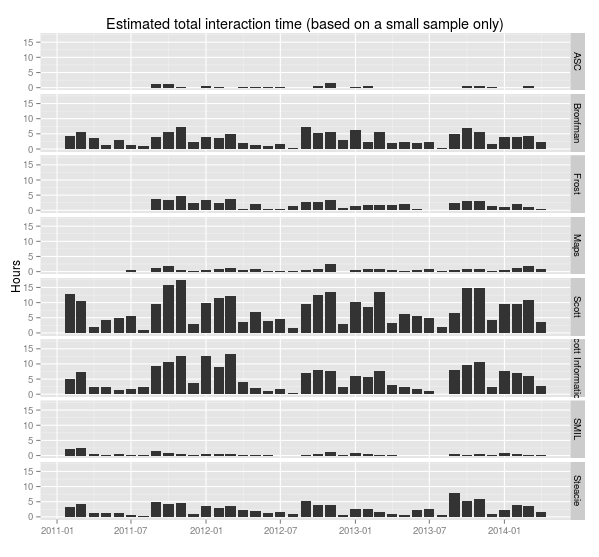
So easy compared to all the confusing stuff I was doing before.
Finally, finding the average duration is just a matter of dividing (mutate comes in dplyr):
> sample.durations.pm <- mutate(sample.durations.pm, average.length = minutes/count)
> sample.durations.pm
Source: local data frame [274 x 5]
Groups: library.name
library.name month minutes count average.length
1 ASC 2011-09-01 77 7 11.000000
2 ASC 2011-10-01 66 2 33.000000
3 ASC 2011-11-01 13 7 1.857143
4 ASC 2012-01-01 41 3 13.666667
5 ASC 2012-02-01 11 5 2.200000
6 ASC 2012-03-01 1 1 1.000000
7 ASC 2012-04-01 4 1 4.000000
8 ASC 2012-05-01 23 3 7.666667
9 ASC 2012-06-01 8 2 4.000000
10 ASC 2012-07-01 4 1 4.000000
.. ... ... ... ... ...
> ggplot(sample.durations.pm, aes(x=month, y=average.length)) + geom_bar(stat="identity") + facet_grid(library.name ~ .) + labs(x="", y="Minutes", title="Estimated average interaction time (based on a small sample only)")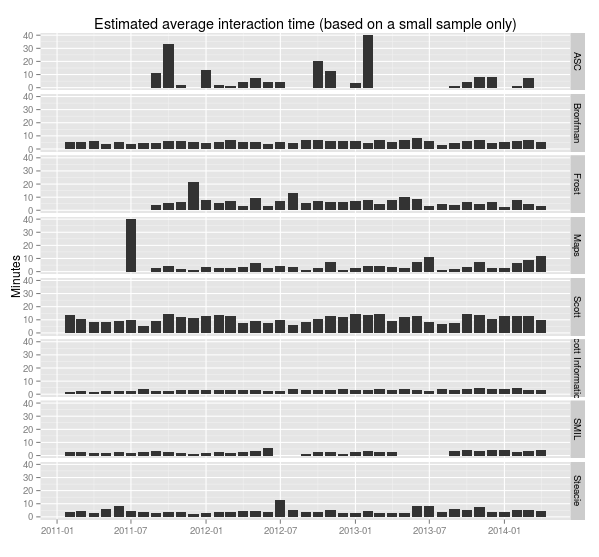
Don’t take those numbers as reflecting the actual real activity going on at YUL. It’s just a sample, and it conflates all kinds of questions, from directional (“where’s the bathroom”), which take 0-1 minutes, to specialized (generally the deep and time-consuming upper-year, grad and faculty questions, or ones requiring specialized subject knowledge), which can take hours. Include the usual warnings about data gathering, analysis, visualization, interpretation, problem(at)ization, etc.