
These are my speaking notes for Stuff, Standards and Sites: Libraries and Archives in AR, a short talk I gave at the March 2014 AR Standards Community Meeting in Arlington, Virginia. (See my blog post about this for a little background, including how I made the slides and these screenshots here.)

I know it’s late in the afternoon. I’m only going to talk for about twenty minutes. I’m talking about libraries and archives, and how our resources and standards fit into augmented reality and its standards. There’s a lot more I could say, and I’ll be writing up more about this, with more detail and links and examples and code snippets, but today I’ll keep it very short.

I’m here today speaking as a librarian, coming from this world of libraries and archives that you might know or you might not, with a few brief messages that I hope will be useful and that you’ll remember. I won’t be going deep into anything, I’ll just be touching on a few examples, but I hope this will set out how libraries fit into all of this standards-using and standards-making world of AR.
The messages are about these three things: stuff, standards and sites.

I’ve also got one question for you. In order to make library resources work to help support augmented reality, is geolocation the missing ingredient? I’ll be coming back to this but bear it in mind.

Stuff.
The key point here is that we have lots of it and we want you to use it. We have lots and lots and lots of stuff and we want you to use it. We want everyone to use it! We want everyone in the entire world to have access to all our resources, physical and online, no matter what they are. Libraries have books, journals, audio, video, special databases and search engines on narrow topics, guides to how to do research on topics, and more. Archives have original papers and manuscripts, photo collections, strange things printed on paper that we call ephemera like posters and broadsheets, ancient books, and more. We have things in print and we have things online. We digitize. We have mind-bogglingly huge amounts of stuff and we want you to use it. Now, sometimes, for licensing reasons, we can’t offer free and open access to some things. We want that to change and we’re working on open access. That’s for another day.
On behalf of all libraries and archives, and museums and galleries, if you’re doing an AR project where we might possibly be of help, ask. Ask your national library or a local university or your local public library. There may be things that you can use, and you will be talking to people who every day love matching people with good content.
Probably, though, when you think about stuff in libraries, you think about books.

When I travel, especially to a new city, I like to do location-specific reading. When I think of novels set in Washington DC, the first writer that comes to mind is George Pelecanos, who for twenty years has been writing crime novels set here. He also worked on The Wire and Treme. If you like 1970s blaxploitation movies, rock and funk, you’ll like King Suckerman. I do, and I did.
If you know about Pelecanos, or this title in particular, and want to find it in your library, it’s pretty easy to do a search. You all know how to do that. Let’s consider this a solved problem. It may not be solved perfectly, but it’s solved. That’s not what I’m hear to talk about.

Pelecanos is very specific about locations (and music and clothes and cars and much else). Here’s a quote from King Suckerman:
Dimitri Karras swung the Ghia into a space in front of 1816 R Street, cut the engine.
“Here we are,” said Karras.
Vivian had a look at the building: a former mansion with a peeling stucco facade, now four floors housing three units per floor, a small yard out front patched with brown where a fat gray cat with huge ears lay on the grass watching a cluster of gnats hover in the air.
This is about location. This isn’t about the book in the usual metadata sense, title and author, now we’re talking about content inside the book.

This is the south side of R Street NW, just west of 16th Street. That’s 1812 on the left and 1818 on the right. The building in the middle has no number (it’s been taken over by the organization in 1818), but it would be 1814 or 1816. Another scene in the book mentions that Dimitri Karras has a bay window so the fictional building is probably based on 1812.
If you were doing a George Pelecanos augmented reality view of Washington then you want to tie all this together! If people want to know about Pelecanos’s DC and see what it looks like, they need something like this. And if they’re in DC in a particular place and want to know what Pelecanos sites are near them, we need to be able to tie together location and content. This is something we can do in apps like Layar or Junaio now, if the user knows the right channel to look for, and the content has already been extracted and geolocated. It’s easy enough to store that in GeoJSON or something similar.
What about standards? How do library standards fit into this? How can a library help a user get to this information?

The huge library consortium OCLC has a service called MapFAST, and you can ask it about (38.912599, -77.04245) and see what it tells you. MapFAST associates locations with subject headings. It gives back JSON, not GeoJSON, but it has a location in it. If you know a location you can ask what subject headings are about places near it. That name, “Washington (D.C.) – Dupont Circle” is a subject heading. It is a Library of Congress Subject Heading. It’s telling us about Dupont Circle because that is the name of the neighbourhood this building is in (and Dupont Circle itself is very near.)
Local librarian Ed Summers, who works at the Library of Congress, made a nice example of this in action. Try Subjects Here in your smartphone now or when you’re back home. It will ask you to share your location with the site, and then it will show you subject headings of what’s around you.

We have all this stuff, such as books like King Suckerman and tens of millions of others, and one of things we do with them is describe what they’re about. We have a few ways of doing this, but a common one is Library of Congress Subject Headings, which come from a building just a little ways away. Once you know a subject heading, you can look it up in any catalogue and find everything else that is about that same subject. There are large “union catalogues” that make this easier to do.
(By the way, LCSH began in 1898. Did your industry have any standards specified back then? Library standards go back a long time. We are good with standards.)
LCSH is the only one for aboutness that I’ll mention today, but there are a number of others. LCSH is a standard we use to describe our stuff.

Now we move on to talking about standards. We use standards to describe our stuff. They are linked together.

You can look up Dupont Circle (Washington, D.C.) at id.loc.gov, a service offered by the Library of Congress. All of the subject headings are listed there, fully described. This is an open standard.

Scroll down the page and it says it’s available in alternate formats. It’s part of the world of linked data!

This is what a fragment of what it looks like in RDF/XML (which is ugly, I know, but that’s what it spits out).
In part it’s described using another standard, MADS, the Metadata Authority Description Schema, which we use for describing what we call “authority records.” Authority records are sources of truth. This is an authority record.
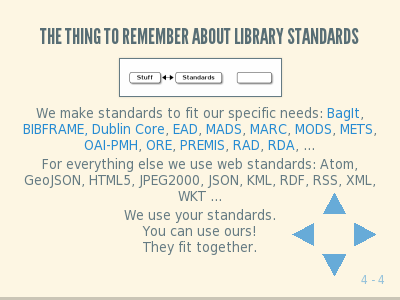
Here’s the thing to remember about standards.
I said about stuff that we have lots of it and we want it to be used, and that the stuff is described by standards.
We make standards to fit our specific needs and purposes: BagIt, BIBFRAME, Dublin Core, EAD, MADS, MARC, MODS, METS, OAI-PMH, ORE, PREMIS, RAD, RDA, …
For everything else we use web standards: Atom, GeoJSON, HTML5, JPEG2000, JSON, KML, RDF, RSS, XML, WKT …
We use your standards. You can use ours! They fit together.

Here’s an example of how they all fit together. A little while ago we knew a location and found out what Library of Congress Subject Headings were about something near it. We can also go in the other direction: if we know an LCSH term, we can find out where it is. Again, this is from that service OCLC offers.
FAST linked data for Washington (D.C.)--Dupont Circle
Sorry again about showing RDF, but notice the ways the data links up and that sameAs assertion that points to GeoNames. This Dupont Circle here is the same as the Dupont Circle in GeoNames!

GeoNames links us to Wikipedia’s entry on Dupont Circle, and then we’ve got lots of resources at hand.

LCSH is just one standard, MADS is another. I’ve talked about how LCSH is just one of our standards that ties in with the rest of the web and web standards. I don’t have enough time to go into details about other standards, but they are out there, in use.
And these standards are used on sites, on our sites and on others’ sites.
There are many out there you might want to know about, but I’ll just highlight a couple of key examples and show you a bit about how they use standards.
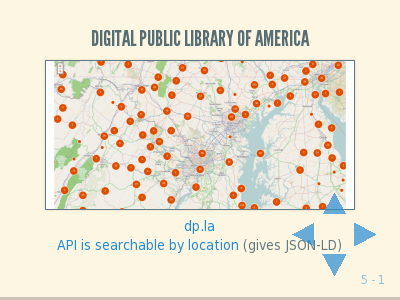
First, the Digital Public Library of America. I know it is about America and we’re not all from here, but we are right here in the centre of the country so I’m using it as the first example. It has about 6,000,000 things in it, bringing together everything (it can) from American libraries, archives and museums. This is digital content, scanned, photographs and more, all of which is available for use. You can look things up by keyword or subject, the traditional way, but also a small portion of the content is geolocated.
Question: is geolocation the missing thing to make all of this more usable in AR?
This is an example of a site with a lot of stuff on it. I remind you: there are sites like this near you, and people working at them that want to help you!

Europeana is similar, but for all of Europe, from many countries; it came before the DPLA and was an inspiration for it. This is another huge site with a vast amount of digital content, ready for use, searchable by subject and keyword. Again, a small portion of it is geolocated.
Again the question: is geolocation the missing ingredient to make all of this more usable in AR?

There are many platforms I could talk about, but the two top FLOSS digital asset management systems are Hydra and Islandora. They are both built on top of Fedora, which is a system for managing digital resources and metadata, and they’re searchable with Solr. Again, with Solr, here we are, using an established platform that’s a de facto standard of its own. Hydra is built on Ruby on Rails, and Islandora is built on Drupal. Check out their web sites for links to sites using both.
There are others, like Dataverse and Omeka and DSpace, which I don’t have time to mention

Here’s an example of something that we’re doing where I work. We have the photographic archives of a defunct newspaper, the Toronto Telegram, and we’re slowly digitizing them.
Some I’m using in a project about the history of a Toronto neighbourhood called Kensington Market. Kensington is right downtown, near Chinatown, and over the last century it’s seen waves of immigrants move in, find their place in Toronto, and move out. This photo here was taken in 1965.
This is some of our stuff. This is a scan of a photograph we have in our archives, which fill up the basement of the library building. The Tele photos take up shelves and shelves and shelves of space. We have about 1.3 million photographs total. That is a lot of stuff.
We’re digitizing them and getting them online, we’re getting our stuff up on our site, and when we do, we describe it and we geolocate it

We describe it with our standards, like MODS, the Metadata Object Description Schema, in which we use LCSH for subject headings.
http://digital.library.yorku.ca/yul-89826/kensington-market/datastream/MODS/view
This is some ugly XML, but notice the cartographic coordinates listed there. This is this standard’s way of giving a location.

Here’s another view, in plain old Dublin Core.
http://digital.library.yorku.ca/yul-89826/kensington-market/datastream/DC/view
dc:coverage there tells you where this photo was taken. This is another standard, accessible on our site, telling you all about our stuff.

It’s also directly searchable with Solr, if you know how to do it and have access (there’s a slight technical problem with doing this directly through Islandora right now).
This is the raw query, you needn’t pay attention to the details, but the point here is that you can ask the site “tell me everything you have that is located within x kilometres of this given point.”
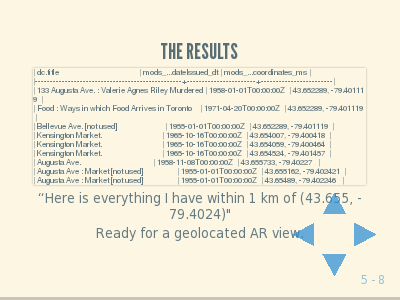
And you get back results like this: a list of all of the resources that we’ve geolocated in Kensington Market.
This shows how you can go from location to “what is around here” for content on a library platform, just as you could do it with the subject headings before, but this time it’s to digitized content done by a local library.

That wraps it up. Everything connects: sites store the standards-described stuff.
- We have lots of stuff and we want you to use it.
- We use standards to describe our stuff.
- Some we made for our specific needs, others are web standards.
- Our sites use the standards to describe the stuff and make it usable.
Back to my question about whether geolocation is the missing ingredient: I showed you a few examples where things are geolocated, so that if you’re in a particular place, you can find out what’s around you. But for the overwhelming majority of the stuff we have, it’s not geolocated. There’s no geographic information associated with it. We can record that information, using our standards, if it’s needed, so what I’d like to know, and you can talk to me after, is if this is something that would be useful for how you see AR developing.